
W tym artykule omawiam podstawowe pojęcia w zakresie optymalizowania strony internetowej. Posiadanie tej wiedzy będzie niezbędne, żeby zacząć działania SEO.
Sprawdź pierwszą część – pojęcia z zakresu wyszukiwarki Google.
Podstawowe pojęcia z zakresu optymalizacji
Jak zauważysz, dużo pojęć jest angielskojęzycznych i chociaż w tym słowniku je tłumaczę, to w komunikacji branżowej często używa się oryginalnych określeń. To cecha całego marketingu online, nie tylko SEO. Dlatego podstawy angielskiego w pozycjonowaniu są wskazane. :-)
Optymalizacja strony
To proces, który przygotowuje stronę do pozycjonowania. W ramach optymalizacji zmienia się nagłówki treści, meta dane, linkowanie wewnętrzne, czy dyrektywy dla wyszukiwarek. Wszystkie te pojęcia omawiam poniżej :-) Optymalizacja opiera się na frazach kluczowych.

Słowa (frazy) kluczowe
Słowa kluczowe są… kluczowe, dlatego ich definicja znajduje się w obu słownikach :-)
Frazy wynikają bezpośrednio z tego, czego szukają użytkownicy w internecie. Słowem kluczowym może być każda fraza, jeśli tylko jest popularna w danej branży. Dla przykładu, moim słowem kluczowym jest marketing i wiele pochodnych.
O słowach kluczowych pisałem już dużo.
Wszystko na temat fraz kluczowych. Cz II
Content (treść)
W SEO treść jest super istotna. Content to nie tylko teksty, ale też obrazy, filmy, a także elementy strony takie, jak nawigacja, nagłówki, stopki itd.
W oczach Google treść dzieli się na:
- Main content – główną treść, która realizuje cel strony. W przypadku tego artykułu, to będą wszystkie definicje.
- Supplementary content – treść uzupełniającą, która nie jest potrzebna do realizacji celu strony, ale nadal stanowi wartość. W przypadku tego artykułu, to będzie pasek boczny, nawigacja, opis autora itd.
- Reklamy – Google jest na nie wyczulony i uważnie obserwuje jaki procent całej treści stanowią reklamy. Nie może być ich za dużo.
O tym, jak ważna jest treść pisałem już wcześniej.

Duplicate content (duplikacja treści)
Każdą treść można skopiować, choćby ten słownik, i umieścić na innej stronie. Google to wykryje i oznaczy tę treść jako duplicate content. Taka treść nie będzie miała wartości.

Meta dane
Każda strona posiada meta dane. To mogą być różne informacje, a łączy je to, że nie są widoczne dla normalnego użytkownika. Można je podejrzeć w kodzie strony, ale to informacja dedykowana wyszukiwarkom.
Podstawowe meta dane dla SEO to:
- Meta title – meta tytuł to około 65 znaków, które Google może umieścić w nagłówku snippeta (patrz słownik #1)
- Meta description – meta opis to około 160 znaków, które Google doda pod nagłówkiem snippeta, jeśli uzna to za stosowne. Google może zignorować meta dane i wyświetlić inne informacje.
Dyrektywy meta robots
To komendy dla wyszukiwarek, które umieszcza się bezpośrednio na stronie. Za pomocą robots=”noindex, nofollow” można zabronić wyszukiwarce indeksacji strony. Te dyrektywy nie są widoczne dla zwykłego użytkownika i nie wpływają na komfort jego wizyty.
Robots.txt
To plik tekstowy (notatnika), który umieszcza się w głównym folderze strony na serwerze. W nim są pierwsze dyrektywy dla wyszukiwarek. Za jego pomocą można zabronić robotom Google (lub innych wyszukiwarek) wejście na konkretne strony, lub wykluczyć całe segmenty stron z indeksu. Plik sprawdzisz wpisując w pasku adresowym zaraz za domeną /robots.txt.

Strony kanoniczne
Za pomocą komendy rel=”canonical” (niewidoczna dla użytkownika) można wskazać, która z wielu podobnych stron ma być traktowana jako oryginalna i indeksowana. Wszystkie duplikaty kierują tą komendą boty do właściwej strony. Google może zignorować to polecenie, jeśli stwierdzi, że błędnie ustaliliśmy priorytety stron.
Link
Link to odnośnik, czyli podstawowa funkcjonalność strony, która pozwala użytkownikowi przejść z jednego miejsca witryny do drugiego. Linki i linkowanie, czyli sieci linków, to kluczowa sfera działań SEO.
Linki dzielimy na:
- wewnętrzne – w obrębie jednej domeny, np. z tego artykułu do poprzedniej części słownika na blogu Samodzielny Marketing,
- i zewnętrzne – czyli linki prowadzące do innych stron, np. stąd do Wikipedii.

Anchor (kotwica)
Każdy link może mieć inny element klikalny – kotwicę. To może być słowo lub całe zdanie, przycisk (button), docelowy adres URL lub obrazek.
Na blogu Samodzielny Marketing stosuję wszystkie te formy, a w linku parę słów wstecz kotwicą (anchorem) jest fraza Samodzielny Marketing.
rel=”nofollow”
Atrybut rel to element linka, którego użytkownik nie widzi. Można go sprawdzić w kodzie strony, a sam atrybut mieści kilka komend dla wyszukiwarki. Najważniejszą dla SEO jest „nofollow”, czyli komenda, żeby bot nie podążał za linkiem i nie brał go pod uwagę przy ustalaniu wagi stron.
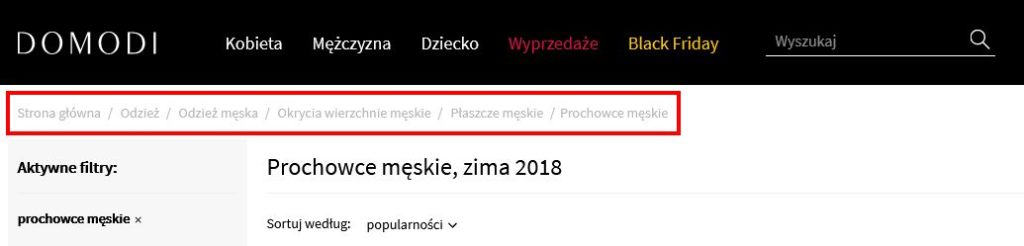
Breadcrumbs
Inaczej okruszki, czyli funkcja, która pokazuje położenie konkretnej strony w domenie, poprzez linkowanie całego drzewa kategorii, do którego strona przynależy.
Atrybuty ALT
Atrybuty ALT są przypisywane zdjęciom i oznaczają tekst alternatywny wyświetlany, gdy dane zdjęcie nie może zostać załadowane. Tekst jest też czytany, jeśli ktoś korzysta z tej funkcji przeglądarki. Atrybut ALT jest bardzo ważny w pozycjonowaniu obrazków.
Nagłówki h1-h6
Każda strona może mieć tytuł i śródtytuły (również ten artykuł). Nagłówki układa się w hierarchii z wykorzystaniem znaczników h1, h2 itd. H1 oznacza najważniejszy tytuł, a samo „h” wzięło się od słowa heading.
Tytuł Nagłówki h1-h6 jest nagłówkiem H3. Kliknij go prawym przyciskiem myszy i wybierz „Zbadaj element” w Firefox lub „Zbadaj” w Chrome. Zobaczysz kod stron i zaznaczony nagłówek w tagach <h3>.
Mapa strony (sitemap)
To nic innego, jak lista linków do istotnych stron w domenie. Dzięki niej bot może szybko dotrzeć do każdej treści bez konieczności przeczesywania wszystkich stron po kolei.
Page Rank (moc strony)
To system oceny stron według tego, jak dużo linków do nich prowadzi. Stworzony przez Google, niegdyś publiczny, teraz używany jest jako luźne określenie mocy strony. Google już go nie stosuje, a przynajmniej nie w znanej nam formie.
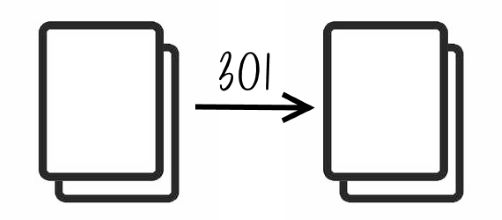
Przekierowanie
Jeśli strona przestaje być potrzebna, można wykonać na niej przekierowanie. Użytkownik, który otworzy adres tej strony, natychmiast zostanie przekierowany na inny. To bardzo przydatne narzędzie, gdy struktura strony się starzeje i wymaga poprawek, a przy tym zmiany adresów stron.
Są różne przekierowania, a najczęstszym stosowanym w SEO jest przekierowanie serwerowe 301, które przekazuje moc starej strony (Page Rank) nowej, do której prowadzi przekierowanie.
.htacces
Plik konfiguracyjny serwera Apache. Za jego pomocą można wdrażać na stronie przekierowania, a także zarządzać dostępami do folderów. Jego obsługa wymaga już większej wiedzy.
To tylko cześć pojęć, które spotkasz na drodze samodzielnej nauki SEO. Poznaj je zanim przejdziemy do zadań optymalizacji Twojej strony www.

Zostaw komentarz