
Wszystko o adresach URL w SEO
Każdy przekaz ma treść i formę. W SEO tę formę tworzy struktura adresów URL. To konkretne adresy grupują content i otrzymują pozycje w wyszukiwarce Google, a więc to one wymagają odpowiedniego zarządzania. Oto kompendium wiedzy na ten temat!
Czym są adresy URL dla Google?
Każda pojedyncza strona jest oceniania pod kątem przydatności, zawartości i dopasowania do zapytań. Google sprawdza też czas ładowania, linki przychodzące i wychodzące, oraz wiele innych czynników.
Natomiast wszystkie te elementy, gdy już algorytmy Google je przetworzą, są przypisywane do konkretnego adresu URL, pod którym znalazła się strona. Innymi słowy, Google ocenia strony, ale ranking przypisuje do adresu URL.
To oznacza, że wszelkie zmiany i błędy w strukturze adresów Twojej witryny mogą mieć fatalne konsekwencje dla ruchu organicznego.
Adresy URL tworzą nawigację
Druga istotna rzecz, to fakt, że z adresów URL powstaje nawigacja. Ta z kolei jest jak mapa całej witryny ze wskazówkami, które konkretne strony są ważne. Adresy URL leżą więc u podstaw linkowania wewnętrznego.
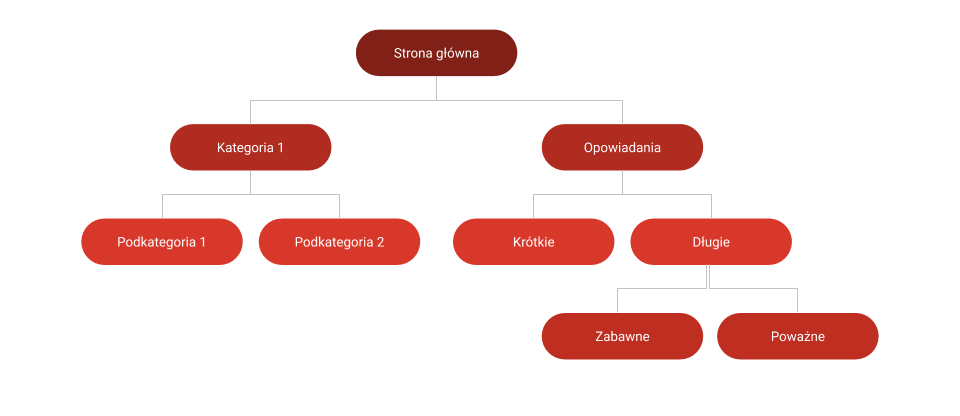
Na temat budowania nawigacji pisałem już tutaj:
Struktura i nawigacja stron w SEO
Kod odpowiedzi serwera dla adresów URL
Google posługuje się statusami odpowiedzi serwera, by porządkować adresy URL, bo wiele z nich powstaje tymczasowo, część się z czasem zmienia, a mnóstwo jest zbędnych.
Czym są kody odpowiedzi serwera?
To informacja w formie prostych ciągów numerycznych, którą zgłasza serwer, gdy Twoja przeglądarka wysyła jakieś żądanie, np. z prośbą o otwarcie konkretnego adresu URL.
Zanim zobaczysz stronę w przeglądarce, serwer informuje, czy strona istnieje, nie istnieje, bądź została przeniesiona, albo celowo zablokowana. Dzięki tym kodom, przeglądarka wie, jaką akcję wykonać.
Najpopularniejsze kody odpowiedzi to:
- 200: strona jest dostępna, przeglądarka może ją wyświetlić,
- 404: strona już nie istnieje, więc przeglądarka informuje o tym użytkownika,
- 301: strona została przeniesiona pod inny adres, więc przeglądarka ładuje nowy adres URL.
To trzy kluczowe dla SEO kody odpowiedzi, ale jest ich znacznie więcej. Np. status 500 oznacza, że serwer po prostu nie działa, a 507, że serwer nie ma miejsca na dysku, by zapisać żądanie (i tym samym wyświetlić stronę). Wszystkie kody odpowiedzi serwera znajdziesz w artykule na Wikipedii.
Statusy odpowiedzi serwera możesz sprawdzać za pomocą wtyczki do przeglądarki. Zarówno Google Chrome i Firefox oferują ich sporo.

Adresy URL są unikatowe
To oznacza, że każda zmiana znaku w adresie URL tworzy dla Google nową stronę, czyli bot od nowa sprawdza kod odpowiedzi oraz wszystkie dyrektywy i zawartość. To bardzo ważne, bo z perspektywy dewelopera drobna zmiana budowy adresów URL nic nie znaczy.
Dla przykładu, wszystkie poniższe adresy będą zawierały tę samą treść:
- https://www.samodzielny-marketing.pl
- http://www.samodzielny-marketing.pl
- http://samodzielny-marketing.pl
- https://samodzielny-marketing.pl
- http://www.samodzielny-marketing.pl/
- https://www.samodzielny-marketing.pl/
- http://samodzielny-marketing.pl/
- https://samodzielny-marketing.pl/
A to tylko wierzchołek góry lodowej!
Dyrektywy dla adresów URL
Jak widzisz, najmniejsza zmiana znaku w adresie URL generuje nowy adres. To problem, dlatego Google posługuje się dyrektywami, by utrzymać w tym bałaganie porządek. Za zgłaszanie odpowiednich dyrektyw odpowiedzialny jesteś Ty!
czytaj więcej:
Podstawy dyrektyw dla botów w SEO
Wśród najważniejszych dyrektyw dla botów jest „noindex”. To główna broń w walce z rozpasaniem witryn, które potrafią generować miliony adresów URL.
Czytaj więcej:
Kanoniczność adresów URL
Oprócz dyrektyw, istnieje funkcjonalność, która pozwala wskazywać, które strony są kanoniczne, czyli oryginalne. Stosujemy ją właśnie dla adresów URL, które różnią się między sobą, ale tak naprawdę zawierają tę samą treść.
Kanoniczność podajemy w nagłówku strony za pomocą tagu:
<link rel=”canonical” href=”https://oryginalnastrona.pl” />
Tag ten wklejamy w źródle strony dla każdego adresu URL . Całe założenie kanoniczności sprowadza się do tego, by na zbędnej stronie podawać link do właściwej, oryginalnej, a więc kanonicznej strony. Na stronie docelowej, tej właściwej, kanoniczność ustawiamy na własny adres URL.

Przekierowania adresów URL
Internet nie stoi w miejscu, a serwisy rosną i się zmieniają, dlatego czasami trzeba przebudować strukturę adresów URL. Zarządzanie taką zmianą to spore wyzwanie, a do tego nigdy tak do końca nie można się pozbyć dawnych stron.
Jeśli jakiś adres URL zbierał ruch i był linkowany z zewnątrz, to zawsze warto go zachować. Jeśli musi zostać usunięty, to należy wykonać przekierowanie strony na nowy adres i jak najdłużej je utrzymywać. To oznacza, że jeśli po jakimś czasie nowy adres też będzie wymagał usunięcia, powstanie skomplikowany ciąg przekierowań. Łatwo się w tym pogubić.
To zawsze problem, dlatego pierwsze i kluczowa zasada przy pracy z SEO dużych serwisów brzmi:
planuj strukturę adresów URL na przyszłość.
Jeśli nie musisz, nie zmieniaj jej!
Przekierowanie 301
Przekierowanie strony to nic innego, jak wskazanie przeglądarce innego adresu URL, który ma wyświetlić. To częsta praktyka i przeglądarki robią to niezauważenie.
Przekierowanie można robić za pomocą języka programowania, np. Java Script, albo z poziomu odpowiedzi serwera. To drugie rozwiązanie jest dużo lepsze. Jak wspomniałem, Google najpierw patrzy na kod odpowiedzi serwera, dlatego jeśli otrzyma status 301, zrozumie że treść została przeniesiona i tak samo przeniesie ocenę rankingową ze starego na nowy adres URL.
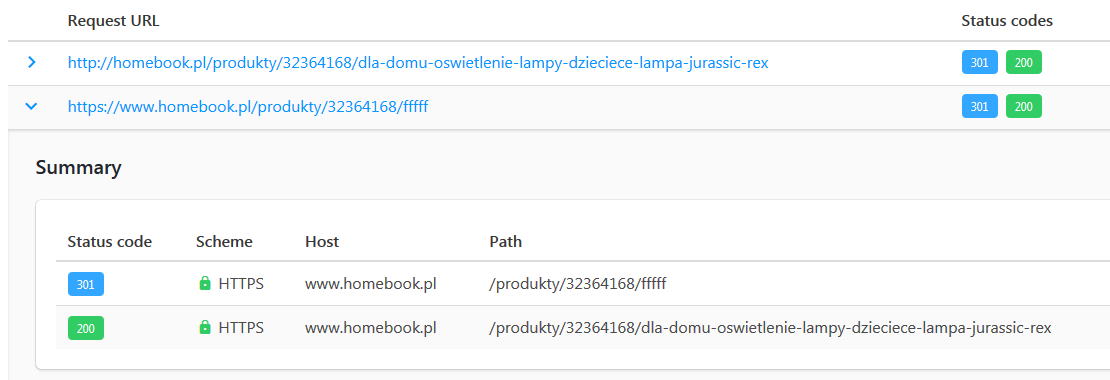
Przypomnę, odpowiedź 301 oznacza, że strona została na zawsze przeniesiona pod inny adres URL. To jedyne przekierowanie, które możemy stosować, jeśli zależy nam na zachowaniu oceny rankingowej w wyszukiwarce.
Istnieje jednak koszt takiego przekierowania. Google zawsze sprawdza, czy pod nowym adresem content jest podobny. Jeśli nie będzie, moc zebrana na starej stronie zostanie stracona. Nawet jeśli nowa strona ma tę samą treść, przeniesiona moc będzie mniejsza.
Kody odpowiedzi, w tym przekierowania 301 sprawdzisz w wielu narzędziach online, np. tutaj.
Linki i adresy URL
Pamiętaj, że link to nie adres URL. Link to funkcjonalność pozwalająca przenieść się na inną stronę www, a jednym z jego elementów jest docelowy adres URL. Link budowany jest przez tag „a href” w kodzie źródłowym, a elementem klikanym (anchor) może być obraz lub tekst.
Link oraz adres URL są jednak mocno powiązane i należy pamiętać, że przy zmianie adresu URL, należy podmienić linki do niego w całej domenie.
Błędne lub zapomniane linki są też głównym powodem wykrywania stron 404 przez Google. Pamiętaj, że bot znajduje strony poprzez linkowanie wewnętrzne, więc jeśli zmieniasz, tworzysz lub usuwasz adresy URL, musisz zaktualizować do nich linki!
To samo tyczy się linków podawanych w pliku sitemapy dla witryny!
Adresy URL obrazów
Nie tylko strony mogą mieć adres URL. Obrazy i pliki też mają adresy URL i o nie trzeba zadbać tak samo, jak o te dla stron HTML. Różnica polega na tym, że obrazki są linkowane poprzez atrybut „img src” w źródle stron HTML. Obrazy z reguły są też częścią strony i nikt nie wyświetla ich osobno.
Natomiast Google do swojej wyszukiwarki obrazów weryfikuje adresy URL zdjęć. One też mogą mieć dyrektywy, oraz być linkowane wewnętrznie. Optymalizuj je!
Najczęstsze problemy z adresami URL
Oto lista kilku częstych problemów, które spotykamy w ramach zarządzania adresami URL. W pojedynkę łatwo je rozwiązać, ale jeśli się skumulują, to mogą spowodować niemały zawrót głowy i obniżenie pozycji w wynikach wyszukiwań.
Zbędne strony
Z reguły, jak powstaje nowy serwis, to tworzone są duże ilości adresów URL, których nikt nie potrzebuje. Często nikt nawet o nich nie wie. To wynika z używanych CMSów, albo braku planowania przy budowie nawigacji.
Trudno temu zapobiec, dlatego dobrze jest wykonać crawl serwisu, który przewertuje wszystkie możliwe linki i znajdzie problematyczne strony. Do takiego audytu potrzebne jest narzędzie, np. Screaming Frog.
Złe dyrektywy
Dodając dyrektywy na stronach, często zapominamy o istnieniu jakichś kombinacji adresów URL i zdarza się, że dyrektywy są wklejane nie tam, gdzie trzeba. Należy na to uważać, zwłaszcza jeśli posługujemy się dyrektywą noindex. Kontrola po wdrożeniu jest wskazana.
Błędy 404
W każdym serwisie znajdują się linki do stron, które nie istnieją. Trudno nad tym zapanować, ale Google zawsze do takich dotrze. W małej skali błędy 404 to nie problem, ale należy co jakiś czas kontrolować serwis pod tym kątem, zwłaszcza jeśli taki problem zgłasza Google Search Console.

Pętle przekierowań
To poważny problem, który może wpłynąć zarówno na ranking w wyszukiwarce, jak i odbiór strony przez użytkownika. Pętla powstaje wtedy, kiedy przekierowujemy strony w taki sposób, że ostatnia w ciągu strona przekierowuje na pierwszą i łańcuch zaczyna się od nowa. To sprawia, że przeglądarka głupieje. Eliminuj takie błędy natychmiast.
Brak aktualizacji linków wewnętrznych
To częsty problem. Zmieniamy nawigację, scalamy strony, zmieniamy nazwy, ale zapominamy, że gdzieś w serwisie mieliśmy mnóstwo linków do starych stron. Porządek w tej kwestii to podstawa dobrej optymalizacji SEO. Przy każdej zmianie, porządkuj linkowanie!
Duplikacja stron i contentu
W sytuacji, gdy mamy dużo stron, a nie uporządkowaliśmy ich przekierowaniami, bądź kanonicznością, tworzy się duplikacja treści. Jak wspomniałem, Google traktuje każdy adres URL jako unikatowy i przez to potrafi wielokrotnie zaindeksować tę samą treść. Taka duplikacja powoduje kanibalizację, co osłabia ogólną ocenę strony i obniża jej pozycje w wyszukiwarce.
Podsumowanie
Jak widać, jest wiele aspektów dotyczących adresów URL, o które trzeba zadbać. Pojedynczo to nie problem, ale jeśli Twoja witryna jest spora i ma też dłuższą historię, to kumulacja wszystkich wyżej wymienionych problemów może przynieść spory ból głowy przy zarządzaniu strukturą adresów URL.
Czytaj dalej o linkowaniu wewnętrznym:

Zostaw komentarz